| Last modified 2025-04-04 | Support |
![]()
Get Started with HISE
 | Abbreviations Key |
| AIFI | Allen Institute for Immunology |
| CertPro | Certificate of Reproducibility |
| CLI | command line interface |
| HISE | Human Immune System Explorer |
| IDE | integrated development environment |
| SDK | software development kit |
| STRIDES | Science and Technology Infrastructure for Discovery, Experimentation, and Sustainability [Initiative] |
| UI | user interface |
At a Glance
The Human Immune System Explorer (HISE), an open science initiative from the Allen Institute for Immunology (AIFI), is a research hub where scientists and analysts can store, analyze, and share data generated by scientists at AIFI and its partner organizations. We welcome your requests and suggestions. For questions about this guide or HISE, contact us at immunology-support@alleninstitute.org.
- Sign In
- Overview
- Accounts and Projects
- Collaboration Space
- Data Ingest
- Advanced Search
- NextGen IDEs
- Visualizations
- Certificates of Reproducibility
Sign In
To access HISE, you must sign in. To do so, use your institutional email address, authenticated with a Google identity.
Instructions
1. From the top navigation menu or the hamburger menu, choose LOGIN.
2. On the Log In page, click Sign In with Google.

3. On the Sign in with Google screen, enter your institutional email address, and click Next.
4. Follow the remaining sign-in prompts, which may vary depending on your institution.
After you sign in, you can access the data and tools applicable to your role. Scientists have access to all results and visualization tools. Analysts have those capabilities and the HISE NextGen IDEs. For more information, see Create Your First NextGen IDE Instance (Tutorial).
Overview
HISE is a one-stop shop for all your research needs, from ingesting data to sharing your research with other scientists and with the public. You can find your data efficiently, create a virtual machine with access to JupyterLab, R, and Python, and download data sets onto your machine to do your analytical work. HISE also supports collaboration by helping you upload your findings, create visualizations, and discuss your scientific insights. The publications option and the Data Apps platform let you share your research privately or showcase it for the public in a polished, visually appealing format.
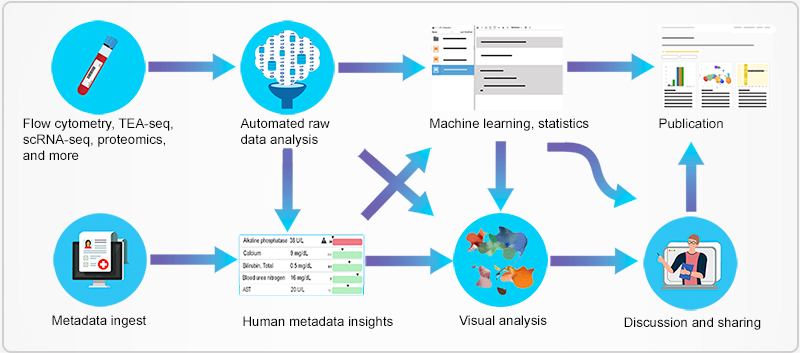
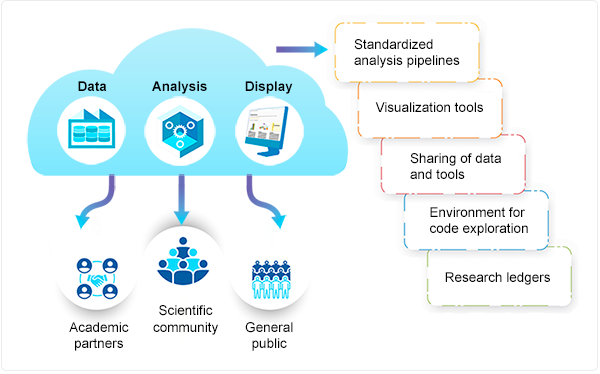
HISE is a data storage, analysis, presentation, and collaboration hub that offers layered access to data and tools. These assets are accessible to AIFI, its academic partners, the broader scientific community, and the public.
Research by AIFI and its academic partners in the wet lab generates samples, which translate to large data sets. This data is analyzed and explored, generating new scientific insights.
Accounts and Projects
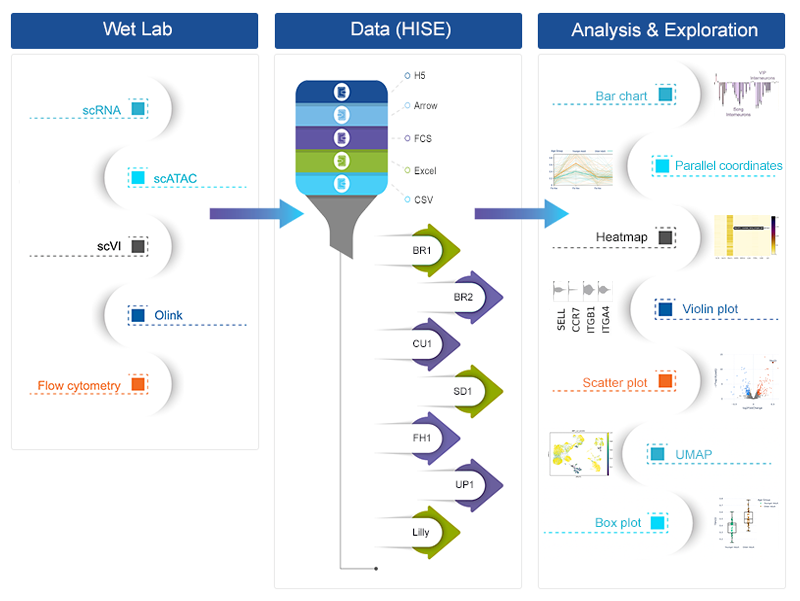
In HISE, an account is a group of scientific collaborators guided by an agreement that outlines the legal obligations of those who access or analyze HISE data. Each account has its own set of restrictions, and sources of funding and data must be kept separate across accounts. Users shouldn't combine or analyze data from various accounts.
You can think of an account as an umbrella for projects. Many research initiatives can be launched under a single HISE account, and these initiatives are known as projects. All projects under an account are related to the organization's overarching research goal, and results from the different projects can be combined for further analysis.
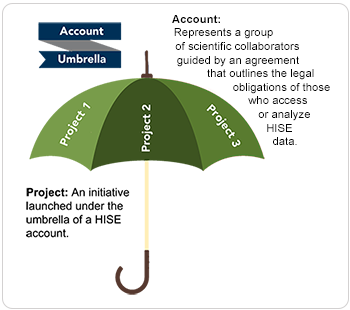
The following illustration shows the relationship between accounts and projects. The diagram shows two separate accounts, A and B. Each account has its own separate data source(s). You can think of each account as a walled garden in which account data is isolated from data in other accounts, the way medical records in one practice are separated from medical records in another practice. This approach safeguards protected health information and keeps billing information private. Within each account, several projects might be created to conduct new research related to the principal research initiative.
It's not always clear whether a new research initiative necessitates a new account, or if a new project would suffice. If the data must be kept absolutely inaccessible to other users, or the research is funded separately, a new account is in order. If the work can be added to an existing research initiative, it can be set up as a new project.
Instructions
To orient yourself in HISE, use the following instructions to explore the Environment section. It shows the currently active account and its associated project(s). Depending on your HISE research activities, you may have access to more than one account or projects.
1. In the upper-right corner of your screen, click your name.
2. From the drop-down list, choose Environment.
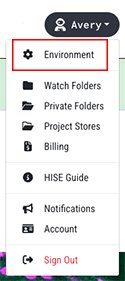
3. On the Configure HISE Environment screen, click Accounts.

4. In the Available Accounts field, choose an account.

5. In the Available Projects field, select the checkbox next to the projects whose data you want to analyze. To select or deselect all projects, use the checkbox to the left of the Name field.
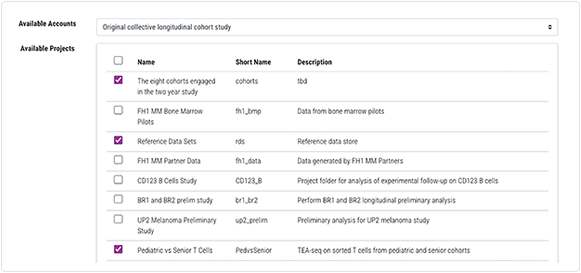
Collaboration Space
The HISE Collaboration Space has access controls that let you work with other scientists to manage file sets, prepare reports, publish studies, coordinate work on publications, and read or contribute to selected other documents and presentations.
Data Ingest
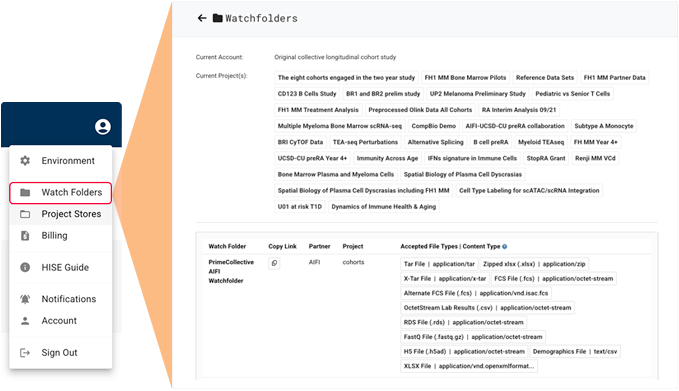
Watchfolders are used to upload data, such as lab results, survey data, and EMR data, and transfer it to HISE for analysis. Each project has a Project Store in which users can save analyses and upload data that's not associated with automated pipelines. To send data to your Project Store, a designated watchfolder must be set up by a HISE administrator. For details, see Understand Watchfolders and the Project Store.
Watchfolder
A watchfolder is like a pickup spot for data that's ready to be ingested. Data does not persist in a watchfolder. If the data meets specified pipeline requirements, it's claimed by an automated pipeline that picks up and processes the data. The files then move to a storage bucket for analysis. Users can locate them there using an advanced search. Then they can download the files to their IDE for secondary analysis. For file formatting instructions, see Use Watchfolders to Ingest Data.
Project Store
Every project has a project-specific, read-only storage space called a Project Store. You can use the Project Store UI to browse file contents, associate files with their corresponding sample references (if you didn't do so during ingestion), preview PDF and JPG files, move files directly into an IDE, mark files for deletion, or upload derived insights for storage.
To see your Project Stores, click the person icon in the upper-right corner of your screen, and choose Project Stores from the drop-down menu. For details, see Ingest Data into the Project Store.

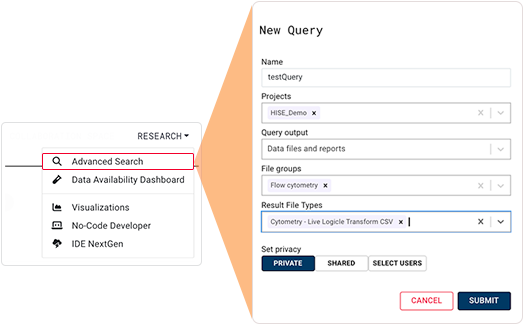
Advanced Search
The powerful advanced search feature in HISE lets you define the subjects, file types, or studies you want to find. Advanced search lets you create queries and filter result files by metadata related to the subject, the sample, CBC results, or pipeline characteristics. The selected search results can then be visualized or sent to an IDE for further inspection. You can also run multiple queries side by side, group the results of each query, and send them to a visualization tool for comparison.
To access this feature from the top navigation menu, click Research, and then choose Advanced Search from the drop-down list. For details, see Use Advanced Search (Tutorial).
NextGen IDEs
When you create and manage IDEs in HISE, you can store intermediate files, schedule notebook jobs, manage IDE state, and save results or visualizations. An IDE is a comprehensive software suite that consolidates various scientific tools and libraries into a unified platform. Working in a HISE NextGen IDE streamlines the data analysis process by providing a centralized space in which to work and visualize your data. You can choose from preinstalled data modalities curated by experienced software developers with the help of leading scientists in flow cytometry, Olink protein analysis, scRNA-seq, single-cell genomics, and other specialized areas. For details about data modalities, see Manage NextGen IDE Packages.
Each of the folders in a HISE NextGen IDE has a different purpose. To learn about folder functions and persistence, see Explore NextGen IDE Folders. If you're ready to get started, see Create Your First NextGen IDE (Tutorial). To learn how to save, stop, restart, delete, or clone an IDE instance, see Manage NextGen IDE Instances (Tutorial).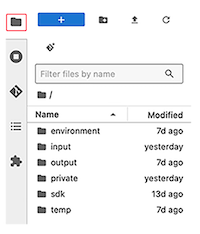
Treat every IDE as a temporary data processing space, not a permanent workspace. Instead of consolidating all research activities into a single IDE, create separate notebooks for specific purposes, such as preprocessing, predictive modeling, and visualization. This task-based approach streamlines your workflow and lowers IDE billing costs, since small instances are easy to stop or delete. To help your team minimize expenses, you should keep track of your IDE usage throughout each month. See the advice in Best Practices for NextGen IDE Users
and the instructions in Track Your IDE Billing Expenses (Tutorial).
Visualizations
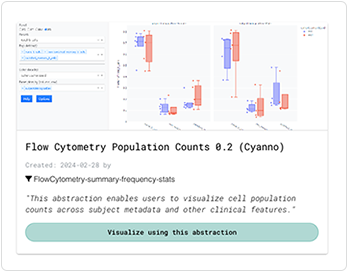
Any HISE user can contribute data visualizations to a study and share them with other researchers. You can save these visualizations using either the advanced search function or an IDE instance.
Regardless of how it was generated, any user can retrieve saved visualizations directly in the study UI. In other words, even if the visualization was generated with an IDE instance, an IDE instance is not needed to see the saved visualization. Using this workflow, analysts can contribute novel visualizations to a study and share them with (non-coding) scientists, as shown in the following shared abstraction.
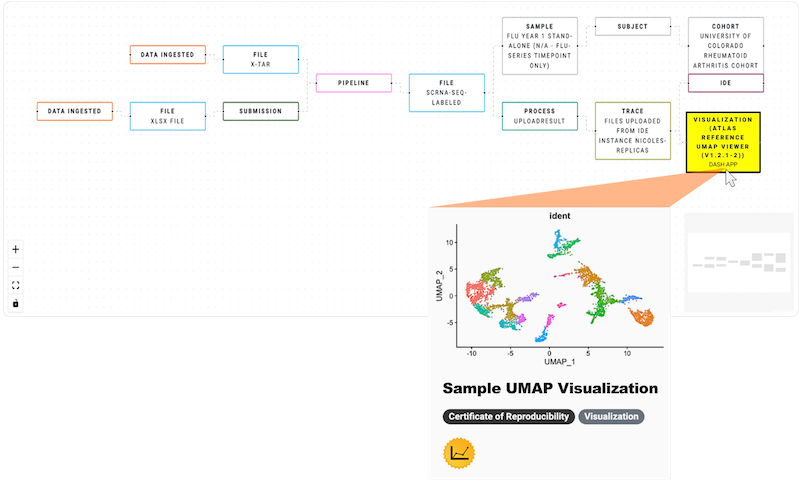
Certificates of Reproducibility (CertPros)
A certificate of reproducibility (CertPro) is a detailed record of your scientific research generated in real time to foster reliable reproducibility of study results. This step-by-step trace includes your data, scientific algorithms, computational environment, tools stack, and results, as shown in this image of a partial certificate. For details, see Create and Use Certificates of Reproducibility (Tutorial).
A workspace is a separate, fully provisioned computational space in which the steps of a CertPro can be re-executed in an environment that mimics the original tool stack. The workspace is built on GCP, and you must have the Google Cloud CLI installed.
HISE or STRIDES Users
Registered HISE users automatically receive workspaces. To find yours, log in to HISE and navigate to COLLABORATION SPACE > Data Apps. Scientists enrolled in STRIDES can use their STRIDES billing ID. For details, see the STRIDES website.
Other Users
If you're not a HISE or STRIDES user, any storage or cloud computing costs you incur are charged directly to your GCP account. Therefore, to establish a workspace, you must have a GCP billing ID. To learn how to create one and start your workspace, see Open a Workspace to Re-Execute a Certificate of Reproducibility.
Data Apps
Data Apps is a dynamic platform that showcases the data and computational resources in HISE, helps scientists apply AIFI research, awards certificates of reproducibility, and encourages exploration. Each Data Apps instance turns a static presentation of scientific research into a versatile asset package that can include multiple studies in a customizable UI. To learn more, see Get Started with Data Apps.
 Related Resources
Related Resources